
OpenCL :: حافظه محلی و گروه ها – تجزیه و تحلیل و پیش بینی – 4 مه 2023
[ad_1] در این وبلاگ من در حال بررسی نحوه عملکرد حافظه محلی با توجه به یک گروه کاری (از موارد کاری) هستم. ما یک هسته ساده ایجاد می کنیم که شناسه ها، شناسه جهانی، شناسه محلی، شناسه گروه یک مورد کاری را صادر می کند. علاوه بر این، یک عدد صحیح محلی را با استفاده

[ad_1]
در این وبلاگ من در حال بررسی نحوه عملکرد حافظه محلی با توجه به یک گروه کاری (از موارد کاری) هستم.
ما یک هسته ساده ایجاد می کنیم که شناسه ها، شناسه جهانی، شناسه محلی، شناسه گروه یک مورد کاری را صادر می کند.
علاوه بر این، یک عدد صحیح محلی را با استفاده از پیشوند __local در تابع هسته نمونهسازی میکنیم.
و آن را افزایش خواهیم داد (++).
حافظه محلی در یک گروه کاری به اشتراک گذاشته می شود، بنابراین با توجه به ارزش آن، خواهیم دید که با اجرا چه اتفاقی می افتد.
متغیر و آن را به شکاف جهانی مورد کاری که در حال اجراست ارسال کنید.
اوه بله، ما همچنین یک آرایه خروجی به همراه شناسه ها خواهیم داشت و مقداری را که مشاهده کرد را در آنجا می اندازیم.
بنابراین در حالی که یک متغیر محلی خواهیم داشت، وضعیت آن را در چندین آیتم کاری دریافت خواهیم کرد.
این کد است:
#property version "1.00" int OnInit() { EventSetMillisecondTimer(33); return(INIT_SUCCEEDED); } void OnDeinit(const int reason) { } void OnTimer(){ EventKillTimer(); int ctx=CLContextCreate(CL_USE_GPU_DOUBLE_ONLY); if(ctx!=INVALID_HANDLE){ string kernel="__kernel void memtests(__global int* global_id," "__global int* local_id," "__global int* group_id," "__global int* output){rn" "//initialized once in local memory for each compute unitrn" "__local int f;" "f++;" "output[get_global_id(0)]=f;" "global_id[get_global_id(0)]=get_global_id(0);" "local_id[get_global_id(0)]=get_local_id(0);" "group_id[get_global_id(0)]=get_group_id(0);}"; string errors=""; int prg=CLProgramCreate(ctx,kernel,errors); if(prg!=INVALID_HANDLE){ ResetLastError(); int ker=CLKernelCreate(prg,"memtests"); if(ker!=INVALID_HANDLE){ int items=8; int global_ids[];ArrayResize(global_ids,items,0); ArrayFill(global_ids,0,items,0); int local_ids[];ArrayResize(local_ids,items,0); ArrayFill(local_ids,0,items,0); int group_ids[];ArrayResize(group_ids,items,0); int output[];ArrayResize(output,items,0); int global_id_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); int local_id_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); int group_id_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); int output_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); CLSetKernelArgMem(ker,0,global_id_handle); CLSetKernelArgMem(ker,1,local_id_handle); CLSetKernelArgMem(ker,2,group_id_handle); CLSetKernelArgMem(ker,3,output_handle); uint offsets[]={0}; uint works[]={items}; CLExecute(ker,1,offsets,works); while(CLExecutionStatus(ker)!=CL_COMPLETE){Sleep(10);} Print("Kernel finished"); CLBufferRead(global_id_handle,global_ids,0,0,items); CLBufferRead(local_id_handle,local_ids,0,0,items); CLBufferRead(group_id_handle,group_ids,0,0,items); CLBufferRead(output_handle,output,0,0,items); int f=FileOpen("OCL\localmemtestlog.txt",FILE_WRITE|FILE_TXT); for(int i=0;i<items;i++){ FileWriteString(f,"GLOBAL.ID["+IntegerToString(i)+"]="+IntegerToString(global_ids[i])+" : LOCAL.ID["+IntegerToString(i)+"]="+IntegerToString(local_ids[i])+" : GROUP.ID["+IntegerToString(i)+"]="+IntegerToString(group_ids[i])+" : OUTPUT["+IntegerToString(i)+"]="+IntegerToString(output[i])+"n"); } FileClose(f); int groups_created=group_ids[0]; for(int i=0;i<ArraySize(group_ids);i++){ if(group_ids[i]>groups_created){groups_created=group_ids[i];} } int compute_units=CLGetInfoInteger(ker,CL_DEVICE_MAX_COMPUTE_UNITS); int kernel_local_mem_size=CLGetInfoInteger(ker,CL_KERNEL_LOCAL_MEM_SIZE); int kernel_private_mem_size=CLGetInfoInteger(ker,CL_KERNEL_PRIVATE_MEM_SIZE); int kernel_work_group_size=CLGetInfoInteger(ker,CL_KERNEL_WORK_GROUP_SIZE); int device_max_work_group_size=CLGetInfoInteger(ctx,CL_DEVICE_MAX_WORK_GROUP_SIZE); Print("Kernel local mem ("+kernel_local_mem_size+")"); Print("Kernel private mem ("+kernel_private_mem_size+")"); Print("Kernel work group size ("+kernel_work_group_size+")"); Print("Device max work group size("+device_max_work_group_size+")"); Print("Device max compute units("+compute_units+")"); Print("Device Local Mem Size ("+CLGetInfoInteger(ctx,CL_DEVICE_LOCAL_MEM_SIZE)+")"); Print("------------------"); Print("Groups created : "+IntegerToString(groups_created+1)); CLKernelFree(ker); CLBufferFree(global_id_handle); CLBufferFree(local_id_handle); CLBufferFree(group_id_handle); CLBufferFree(output_handle); }else{Print("Cannot create kernel");} CLProgramFree(prg); }else{Alert(errors);} CLContextFree(ctx); } else{ Print("Cannot create ctx"); } }
محتویات آرایه های id و آرایه خروجی را به یک فایل خروجی می دهیم و آنها را بررسی می کنیم. بیایید آن را برای 8 مورد اجرا کنیم، ما باید از 256 مورد در این دستگاه پیشی بگیریم تا شروع به تقسیم خودکار به گروههای گزارش شده توسط اندازه گروه کاری هسته ،ما 8 مورد داریم و بنابراین فقط 1 گروه وجود خواهد داشت.
این هم خروجی فایل:
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : OUTPUT[0]=1 GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : OUTPUT[1]=1 GLOBAL.ID[2]=2 : LOCAL.ID[2]=2 : GROUP.ID[2]=0 : OUTPUT[2]=1 GLOBAL.ID[3]=3 : LOCAL.ID[3]=3 : GROUP.ID[3]=0 : OUTPUT[3]=1 GLOBAL.ID[4]=4 : LOCAL.ID[4]=4 : GROUP.ID[4]=0 : OUTPUT[4]=1 GLOBAL.ID[5]=5 : LOCAL.ID[5]=5 : GROUP.ID[5]=0 : OUTPUT[5]=1 GLOBAL.ID[6]=6 : LOCAL.ID[6]=6 : GROUP.ID[6]=0 : OUTPUT[6]=1 GLOBAL.ID[7]=7 : LOCAL.ID[7]=7 : GROUP.ID[7]=0 : OUTPUT[7]=1
ما می توانیم تمام شناسه های چاپ شده و خروجی را ببینیم، همه مقادیر 1 هستند.
احتمالاً انتظار داشتید که از آنجایی که همه این موارد به طور همزمان اجرا میشوند، مقدار اولیهای که قبل از ++’ed آن را مشاهده کردند، 0 باشد.
مشخصات بیان می کند که ما عدد صحیح محلی f را برای واحد محاسباتی نمونه سازی می کنیم اما یک گروه کاری در یک واحد محاسباتی اجرا می شود، بنابراین سوال بعدی این است که آیا آن را در هر گروه کاری نیز نمونه سازی می کنیم؟
بیایید پیدا کنیم، بیایید یک محلی اضافه کنیم[] همانطور که در وبلاگ های قبلی مشاهده شد، تابع execute را ارسال کنید تا کار به 2 گروه کاری با 4 مورد کاری تقسیم شود.
احتمالاً همان خروجی را خواهیم دید و تنها تغییر در شناسه های محلی و شناسه های گروه خواهد بود
این خطی است که در بالای تابع execute اضافه می کنیم و برای استفاده از آن فقط آن را به عنوان آخرین آرگومان در تابع اجرا اضافه می کنیم.
(در این بعد در هر گروه 4 مورد را مشخص می کنیم)
uint local[]={4}; CLExecute(ker,1,offsets,works,local);
همانطور که انتظار می رود کد ما 2 گروه ایجاد می کند:
2023.05.04 00:59:05.922 blog_simple_local_mem_operation (USDJPY,H1) Groups created : 2
و این هم فایل خروجی:
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : OUTPUT[0]=1 GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : OUTPUT[1]=1 GLOBAL.ID[2]=2 : LOCAL.ID[2]=2 : GROUP.ID[2]=0 : OUTPUT[2]=1 GLOBAL.ID[3]=3 : LOCAL.ID[3]=3 : GROUP.ID[3]=0 : OUTPUT[3]=1 GLOBAL.ID[4]=4 : LOCAL.ID[4]=0 : GROUP.ID[4]=1 : OUTPUT[4]=1 GLOBAL.ID[5]=5 : LOCAL.ID[5]=1 : GROUP.ID[5]=1 : OUTPUT[5]=1 GLOBAL.ID[6]=6 : LOCAL.ID[6]=2 : GROUP.ID[6]=1 : OUTPUT[6]=1 GLOBAL.ID[7]=7 : LOCAL.ID[7]=3 : GROUP.ID[7]=1 : OUTPUT[7]=1
همانطور که انتظار می رود، عدد صحیح حافظه محلی f در هر گروه کاری نمونه سازی می شود (یا تخصیص می یابد؟ آنچه شما آن را می نامید).
عالی.
اما اگر بخواهید مقدار (f) در آیتم کاری برای استفاده از آن افزایش یابد، چه؟
دستوراتی برای انجام این کار با پیشوند atomic_ وجود دارد، در این مورد ما به atomic_inc علاقه مند هستیم.
کاری که آنها انجام میدهند اساساً «محافظت» از ناحیه اطراف متغیر f است تا زمانی که مورد کاری آن را تغییر دهد، بنابراین حدس میزنم که ضربه کوچکی روی سرعت داشته باشد.
(امیدوارم توضیح را در اینجا نگفته باشم)
بنابراین بیایید نسخهای از موارد بالا بنویسیم که هم ارزش اتمی و هم غیر اتمی را صادر میکند، بر این اساس آنها را نامگذاری میکنیم.
کد اکنون به شکل زیر است:
void OnTimer(){ EventKillTimer(); int ctx=CLContextCreate(CL_USE_GPU_DOUBLE_ONLY); if(ctx!=INVALID_HANDLE){ string kernel="__kernel void memtests(__global int* global_id," "__global int* local_id," "__global int* group_id," "__global int* atomic_output," "__global int* non_atomic_output){rn" "//initialized once in local memory for each compute unitrn" "__local int with_atomic,without_atomic;" "with_atomic=0;" "without_atomic=0;" "atomic_inc(&with_atomic);" "without_atomic++;" "atomic_output[get_global_id(0)]=with_atomic;" "non_atomic_output[get_global_id(0)]=without_atomic;" "global_id[get_global_id(0)]=get_global_id(0);" "local_id[get_global_id(0)]=get_local_id(0);" "group_id[get_global_id(0)]=get_group_id(0);}"; string errors=""; int prg=CLProgramCreate(ctx,kernel,errors); if(prg!=INVALID_HANDLE){ ResetLastError(); int ker=CLKernelCreate(prg,"memtests"); if(ker!=INVALID_HANDLE){ int items=8; int global_ids[];ArrayResize(global_ids,items,0); ArrayFill(global_ids,0,items,0); int local_ids[];ArrayResize(local_ids,items,0); ArrayFill(local_ids,0,items,0); int group_ids[];ArrayResize(group_ids,items,0); int atomic_output[];ArrayResize(atomic_output,items,0); int non_atomic_output[];ArrayResize(non_atomic_output,items,0); int global_id_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); int local_id_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); int group_id_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); int atomic_output_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); int non_atomic_output_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); CLSetKernelArgMem(ker,0,global_id_handle); CLSetKernelArgMem(ker,1,local_id_handle); CLSetKernelArgMem(ker,2,group_id_handle); CLSetKernelArgMem(ker,3,atomic_output_handle); CLSetKernelArgMem(ker,4,non_atomic_output_handle); uint offsets[]={0}; uint works[]={items}; uint local[]={4}; CLExecute(ker,1,offsets,works,local); while(CLExecutionStatus(ker)!=CL_COMPLETE){Sleep(10);} Print("Kernel finished"); CLBufferRead(global_id_handle,global_ids,0,0,items); CLBufferRead(local_id_handle,local_ids,0,0,items); CLBufferRead(group_id_handle,group_ids,0,0,items); CLBufferRead(atomic_output_handle,atomic_output,0,0,items); CLBufferRead(non_atomic_output_handle,non_atomic_output,0,0,items); int f=FileOpen("OCL\localmemtestlog.txt",FILE_WRITE|FILE_TXT); for(int i=0;i<items;i++){ FileWriteString(f,"GLOBAL.ID["+IntegerToString(i)+"]="+IntegerToString(global_ids[i])+" : LOCAL.ID["+IntegerToString(i)+"]="+IntegerToString(local_ids[i])+" : GROUP.ID["+IntegerToString(i)+"]="+IntegerToString(group_ids[i])+" : ATOMIC.OUTPUT["+IntegerToString(i)+"]="+IntegerToString(atomic_output[i])+" : NON-ATOMIC.OUTPUT["+IntegerToString(i)+"]="+IntegerToString(non_atomic_output[i])+"n"); } FileClose(f); int groups_created=group_ids[0]; for(int i=0;i<ArraySize(group_ids);i++){ if(group_ids[i]>groups_created){groups_created=group_ids[i];} } int compute_units=CLGetInfoInteger(ker,CL_DEVICE_MAX_COMPUTE_UNITS); int kernel_local_mem_size=CLGetInfoInteger(ker,CL_KERNEL_LOCAL_MEM_SIZE); int kernel_private_mem_size=CLGetInfoInteger(ker,CL_KERNEL_PRIVATE_MEM_SIZE); int kernel_work_group_size=CLGetInfoInteger(ker,CL_KERNEL_WORK_GROUP_SIZE); int device_max_work_group_size=CLGetInfoInteger(ctx,CL_DEVICE_MAX_WORK_GROUP_SIZE); Print("Kernel local mem ("+kernel_local_mem_size+")"); Print("Kernel private mem ("+kernel_private_mem_size+")"); Print("Kernel work group size ("+kernel_work_group_size+")"); Print("Device max work group size("+device_max_work_group_size+")"); Print("Device max compute units("+compute_units+")"); Print("Device Local Mem Size ("+CLGetInfoInteger(ctx,CL_DEVICE_LOCAL_MEM_SIZE)+")"); Print("------------------"); Print("Groups created : "+IntegerToString(groups_created+1)); CLKernelFree(ker); CLBufferFree(global_id_handle); CLBufferFree(local_id_handle); CLBufferFree(group_id_handle); CLBufferFree(atomic_output_handle); CLBufferFree(non_atomic_output_handle); }else{Print("Cannot create kernel");} CLProgramFree(prg); }else{Alert(errors);} CLContextFree(ctx); } else{ Print("Cannot create ctx"); } }
بنابراین در هر گروه متغیرهای with_atomic و without_atomic را مقداردهی اولیه می کنیم
و ما ارزش آنها را نیز صادر خواهیم کرد. بیایید آن را با همان آیتم ها و آیتم های محلی اجرا کنیم
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : ATOMIC.OUTPUT[0]=4 : NON-ATOMIC.OUTPUT[0]=1
GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : ATOMIC.OUTPUT[1]=4 : NON-ATOMIC.OUTPUT[1]=1
GLOBAL.ID[2]=2 : LOCAL.ID[2]=2 : GROUP.ID[2]=0 : ATOMIC.OUTPUT[2]=4 : NON-ATOMIC.OUTPUT[2]=1
GLOBAL.ID[3]=3 : LOCAL.ID[3]=3 : GROUP.ID[3]=0 : ATOMIC.OUTPUT[3]=4 : NON-ATOMIC.OUTPUT[3]=1
GLOBAL.ID[4]=4 : LOCAL.ID[4]=0 : GROUP.ID[4]=1 : ATOMIC.OUTPUT[4]=4 : NON-ATOMIC.OUTPUT[4]=1
GLOBAL.ID[5]=5 : LOCAL.ID[5]=1 : GROUP.ID[5]=1 : ATOMIC.OUTPUT[5]=4 : NON-ATOMIC.OUTPUT[5]=1
GLOBAL.ID[6]=6 : LOCAL.ID[6]=2 : GROUP.ID[6]=1 : ATOMIC.OUTPUT[6]=4 : NON-ATOMIC.OUTPUT[6]=1
GLOBAL.ID[7]=7 : LOCAL.ID[7]=3 : GROUP.ID[7]=1 : ATOMIC.OUTPUT[7]=4 : NON-ATOMIC.OUTPUT[7]=1
Aaaand ما thiiis …. هوم
اتمی آخرین مقداری را که داشت به ما می دهد چرا؟
خوب اگر به کد نگاه کنیم -به آرایه جهانی with_atomic_output- مقدار متغیر محلی را تقریباً در پایان اجرای گروه کاری ارسال می کنیم.
پس این را تصور کنید:
- 4 مورد کاری (از گروه اول) برای اجرا وارد واحد محاسبات می شود
- هر یک به یک عنصر پردازش اختصاص داده می شود
- CU 2 عدد صحیح با_اتمی و بدون_اتمی را مقداردهی اولیه می کند
- هر آیتم کاری به صورت موازی شروع به اجرا می کند
- به طور کلی یک محاسبه بسیار سریعتر از انتقال به حافظه جهانی است
- و می توان گفت که غیر از atomic_inc(); عملکرد هیچ چیز دیگری مانع از آن نمی شود
آیتم های کاری تا زمانی که هر یک به نقطه ای برسد که قرار است داده ها را به آرایه with_atomic برگرداند. - بنابراین در زمانی که هر آیتم به مرحله خروجی می رسد مقدار with_atomic از قبل 4 است.
اگر یک int خصوصی در تماس اتمی قرار دهیم و 1 را به آن اضافه کنیم، ممکن است بتوانیم آن را ببینیم.
مستندات khronos این را برای atomic_inc() بیان می کند.
مقدار 32 بیتی را بخوانید (به عنوان قدیمی ) در مکان مشخص شده توسط پ . محاسبه ( قدیمی + 1) و نتیجه را در مکان مشخص شده ذخیره کنید پ . تابع برمی گردد قدیمی .
بنابراین به ما می گوید که اگر یک عدد صحیح را در سمت چپ فراخوانی اتمی قرار دهیم، مقدار قدیمی متغیر محلی را دریافت خواهیم کرد.
این بدان معناست که متغیر محلی قفل می شود و سپس عدد صحیح خصوصی در آن نقطه مقدار را دریافت می کند، سپس عملیات (++ زیرا inc()) روی متغیر محلی اتفاق می افتد و سپس قفل آن باز می شود. بنابراین ما مقدار “استفاده شده” از این مورد را دریافت می کنیم.
سپس متغیری که داریم خصوصی خواهد بود، روی آن +1 می زنیم و مقدار را در آن نمونه می گیریم!
بیایید آن را نیز در واقع صادر کنیم.
یک بافر دیگر اضافه می کنیم، یک آرگومان دیگر، بافر را به هسته پیوند می دهیم، مقدار را در انتها بازیابی می کنیم، آن را در فایل چاپ می کنیم و فراموش نمی کنیم که بافر را آزاد کنیم.
اکنون، هسته برای بخشی که “قدیمی” را از فراخوانی اتمی دریافت می کند، به این شکل است:
int this_item_only; this_item_only=atomic_inc(&with_atomic)+1;
برای هر آیتم یک int خصوصی به نام this_item_only ایجاد می کند، سپس مقدار قدیمی متغیر محلی with_atomic را می گیرد و یک عدد به آن اضافه می کند.
-excuse my variable names , it for test , and from the multiple tests is run –
این هم خروجی فایل:
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : ATOMIC.OUTPUT[0]=4 : NON-ATOMIC.OUTPUT[0]=1 : INSTANCE.OUTPUT[0]=1
GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : ATOMIC.OUTPUT[1]=4 : NON-ATOMIC.OUTPUT[1]=1 : INSTANCE.OUTPUT[1]=2
GLOBAL.ID[2]=2 : LOCAL.ID[2]=2 : GROUP.ID[2]=0 : ATOMIC.OUTPUT[2]=4 : NON-ATOMIC.OUTPUT[2]=1 : INSTANCE.OUTPUT[2]=3
GLOBAL.ID[3]=3 : LOCAL.ID[3]=3 : GROUP.ID[3]=0 : ATOMIC.OUTPUT[3]=4 : NON-ATOMIC.OUTPUT[3]=1 : INSTANCE.OUTPUT[3]=4
GLOBAL.ID[4]=4 : LOCAL.ID[4]=0 : GROUP.ID[4]=1 : ATOMIC.OUTPUT[4]=4 : NON-ATOMIC.OUTPUT[4]=1 : INSTANCE.OUTPUT[4]=1
GLOBAL.ID[5]=5 : LOCAL.ID[5]=1 : GROUP.ID[5]=1 : ATOMIC.OUTPUT[5]=4 : NON-ATOMIC.OUTPUT[5]=1 : INSTANCE.OUTPUT[5]=2
GLOBAL.ID[6]=6 : LOCAL.ID[6]=2 : GROUP.ID[6]=1 : ATOMIC.OUTPUT[6]=4 : NON-ATOMIC.OUTPUT[6]=1 : INSTANCE.OUTPUT[6]=3
GLOBAL.ID[7]=7 : LOCAL.ID[7]=3 : GROUP.ID[7]=1 : ATOMIC.OUTPUT[7]=4 : NON-ATOMIC.OUTPUT[7]=1 : INSTANCE.OUTPUT[7]=4
جهنم آره
اکنون اولین باری که این کار را انجام دادم از 512 مورد (به جای 8 مورد) استفاده کردم که به من امکان داد یک مشکل احتمالی دیگر را پیدا کنم:
من مقادیر “ATOMIC.OUTPUT” را به جای 256 در گروه دوم 224 دریافت می کردم (اندازه گروه 256 در هر گروه بود، 2 گروه)
که با جبران در اجرا برای برخی از موارد کار انجام شد.
بخش atomic_inc هنوز و در همان زمان 224 آیتم کاری دیگر به مراحل حافظه جهانی صادر شده بودند و بنابراین 224 مورد را به عنوان خروجی اتمی گزارش کردند.
در اینجا یک شماتیک وجود دارد:
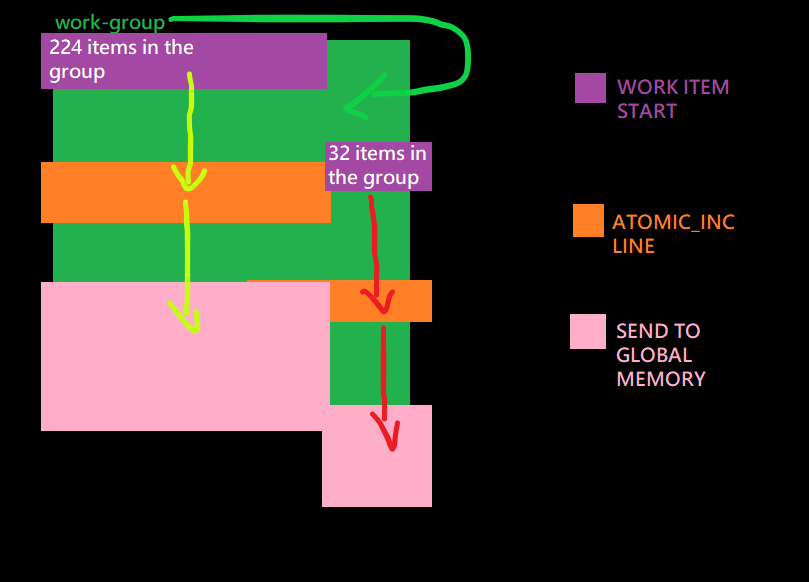
224 آیتم زمانی به بخش حافظه جهانی می رسند که 32 مورد بازنشانی هنوز به قسمت atomic_inc نرسیده باشند.
شما راه حل مقالات و راه حل آن را دیده اید.
کاری که مانع انجام می دهد این است که همه اقلام گروه را در خطی که آن را در آن قرار می دهید متوقف کند تا زمانی که همه اقلام گروه دیگر به آن خط نیز برسند.
که مشکل را حل کرد این خط کد است:
barrier(CLK_GLOBAL_MEM_FENCE);
اگر ما CLK_LOCAL_MEM_FENCE را مشخص میکردیم، آنگاه آیتمهای IN THE GROUP نمیتوانند کاری برای حافظه محلی انجام دهند تا زمانی که همه موارد آن گروه به آن خط برخورد کنند.
به نظر شما این خط کجا رفت؟
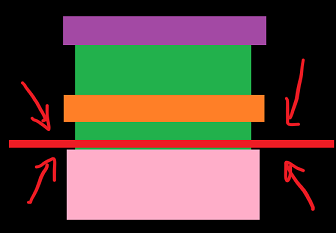
درست است، قبل از صادرات به حافظه جهانی.
من کد منبع نهایی را پیوست می کنم.
به سلامتی

[ad_2]
لینک منبع : هوشمند نیوز
 آموزش مجازی مدیریت عالی حرفه ای کسب و کار Post DBA آموزش مجازی مدیریت عالی حرفه ای کسب و کار Post DBA+ مدرک معتبر قابل ترجمه رسمی با مهر دادگستری و وزارت امور خارجه |  آموزش مجازی مدیریت عالی و حرفه ای کسب و کار DBA آموزش مجازی مدیریت عالی و حرفه ای کسب و کار DBA+ مدرک معتبر قابل ترجمه رسمی با مهر دادگستری و وزارت امور خارجه |  آموزش مجازی مدیریت کسب و کار MBA آموزش مجازی مدیریت کسب و کار MBA+ مدرک معتبر قابل ترجمه رسمی با مهر دادگستری و وزارت امور خارجه |
 مدیریت حرفه ای کافی شاپ |  حقوقدان خبره |  سرآشپز حرفه ای |
 آموزش مجازی تعمیرات موبایل آموزش مجازی تعمیرات موبایل |  آموزش مجازی ICDL مهارت های رایانه کار درجه یک و دو |  آموزش مجازی کارشناس معاملات املاک_ مشاور املاک آموزش مجازی کارشناس معاملات املاک_ مشاور املاک |
- نظرات ارسال شده توسط شما، پس از تایید توسط مدیران سایت منتشر خواهد شد.
- نظراتی که حاوی تهمت یا افترا باشد منتشر نخواهد شد.
- نظراتی که به غیر از زبان فارسی یا غیر مرتبط با خبر باشد منتشر نخواهد شد.





ارسال نظر شما
مجموع نظرات : 0 در انتظار بررسی : 0 انتشار یافته : 0