
ساده ترین شبکه عصبی گیت XOR برای mql5 🍺 قسمت 2 – شبکه های عصبی – 3 آوریل 2023
[ad_1] قسمت 1 این را اینجا بخوانید باشه . چه چیزی داریم: گره ها، لایه ها و شبکه و توابع فید فوروارد. بنابراین در طیف “یک مشکل” به چه معناست؟ به این معنی که اگر مشکل ما دارای پارامترها/ویژگی هایی باشد می توانیم آنها را از طریق لایه ورودی ارسال کنیم و یک پیش بینی

[ad_1]
قسمت 1 این را اینجا بخوانید
باشه .
چه چیزی داریم: گره ها، لایه ها و شبکه و توابع فید فوروارد.
بنابراین در طیف “یک مشکل” به چه معناست؟
به این معنی که اگر مشکل ما دارای پارامترها/ویژگی هایی باشد می توانیم آنها را از طریق لایه ورودی ارسال کنیم و یک پیش بینی یا پیش بینی از شبکه دریافت کنیم.
اکنون مشکل این است که شبکه در حال حدس زدن است زیرا در حالت تصادفی است.
برای آموزش آن چه باید بکنیم؟ ما باید نمونه هایی را با یک پاسخ صحیح شناخته شده دریافت کنیم، ویژگی های آنها را در لایه ورودی قرار دهیم، شبکه را محاسبه کنیم و پاسخ صحیح را با پیش بینی شبکه ها مقایسه کنیم.
بله، نه، لورنسو، ما می دانیم که، بنابراین، هر وزن در شبکه مسئول پیش بینی درست یا غلط ما است.
وقتی این پیشبینی اشتباه است، میخواهیم متوجه شویم که چقدر اشتباه میکنیم و در جهت مخالف حرکت کنیم. من به مشتقات و اینکه چرا از قانون زنجیره ای و همه چیز استفاده می کنیم دست نمی زنم، اگر شما علاقه مند هستید من دیگری دارم همچنین یک وبلاگ بسیار جدی در مورد آن در اینجا
بنابراین، برای کار، چیزی که همیشه می شنوید این است که ما این تابع از دست دادن را داریم و خطا را محاسبه می کنیم و خطای blablalba را منتشر می کنیم. در تفکر کد چه کاری باید انجام دهیم؟
بیایید ابتدا ساختار گره را بررسی کنیم.
class snn_node{ public: double weights[]; double weight_adjustments[]; double bias,bias_adjustment; double error; double output; snn_node(void){reset();} ~snn_node(void){reset();} void reset(){ ArrayFree(weights); ArrayFree(weight_adjustments); bias=0.0; bias_adjustment=0.0; error=0.0; output=0.0; } void setup(int nodes_of_previous_layer, bool randomize_weights=true, double weights_min=-1.0, double weights_max=1.0){ ArrayResize(weights,nodes_of_previous_layer,0); ArrayResize(weight_adjustments,nodes_of_previous_layer,0); ArrayFill(weight_adjustments,0,nodes_of_previous_layer,0.0); if(randomize_weights){ init_weights(weights_min,weights_max); }else{ ArrayFill(weights,0,nodes_of_previous_layer,1.0); bias=1.0; } } void init_weights(double min,double max){ double range=max-min; for(int i=0;i<ArraySize(weights);i++){ weights[i]=(((double)MathRand())/32767.0)*range+min; } bias=(((double)MathRand())/32767.0)*range+min; } void feed_forward(snn_node &previous_layer_nodes[]){ output=0.0; error=0.0; for(int i=0;i<ArraySize(previous_layer_nodes);i++){ output+=previous_layer_nodes[i].output*weights[i]; } output+=bias; output=activationSigmoid(output); } void reset_weight_adjustments(){ for(int i=0;i<ArraySize(weight_adjustments);i++){ weight_adjustments[i]=0.0; } bias_adjustment=0.0; } };
ما یک تابع پس انتشار خواهیم ساخت.
در زمانی که این تابع برای این گره فراخوانی می شود، به این معنی است که خطا را از گره های لایه بعدی که این گره مسئول آن است، خلاصه کرده ایم.
اما خطای تولید شده توسط خروجی است که تابع فعال سازی این گره را طی کرده است. درست ؟ پس باید چکار کنیم؟ ما باید شیب آن یا اثری که گره روی شبکه دارد را بدست آوریم، چگونه؟ با مشتق … (احتمالاً تا به حال از آن کلمه متنفر هستید).
بنابراین، ابتدا چه کار کنیم؟ ما خطای دریافت شده را در مشتق تابع فعال سازی ضرب می کنیم. آسان و چه چیزی برای این تابع نیاز داریم؟
2 چیز:
- اینکه آیا باید خطا را به لایه قبلی ارسال کنیم یا نه (در صورتی که این لایه 1 باشد و لایه قبل از آن لایه ورودی باشد و لایه ورودی “یاد نمی گیرد”)
- آرایه گره های لایه قبلی
خوب بیایید آن را بسازیم:
void back_propagation(bool propagate_error, snn_node &previous_layer_nodes[]){ error*=derivativeSigmoid(output); }
ببینید خطا همان چیزی است که از سمت راست این لایه برای این گره دریافت کرده بودیم و فقط آن را در مشتق سیگموئید ضرب می کنیم.
سرد .
حالا اگر پست دیگر را خوانده باشید، دید تازهای در مورد مشتقات این فرآیند و چرایی آنها دارید، اما اجازه دهید دوباره به طور خلاصه به آن اشاره کنیم:
برای یک گره وزن هایی داریم که در مقادیر خروجی گره های لایه قبلی ضرب می شوند و وارد کادری می شوند که آنها را جمع می کند.
بنابراین تأثیر هر وزن بر مجموع، و خطا بر اساس گسترش، به خروجی گره لایه قبلی که به آن متصل می شود بستگی دارد (به این ترتیب می خواهیم تنظیم مورد نیاز برای این وزن را محاسبه کنیم). کاملا منطقی است درست است؟
مجموع در این گره مقادیری را دریافت می کند و یک وزن با قدر “خروجی گره ای که به آن متصل می شود” بر جمع تأثیر می گذارد.
این وزن چقدر بر مجموع وارد شده به فعال سازی تأثیر گذاشته است به نسبت مقداری است که این وزن بر اساس خطای ایجاد شده توسط این گره تغییر می کند. درست ؟
ببینید چقدر ساده است، به یاد داشته باشید که ما تنظیمات وزن را در آرایه معادل ذخیره می کنیم (شبکه هنوز در حال یادگیری نیست)
void back_propagation(bool propagate_error, snn_node &previous_layer_nodes[]){ error*=derivativeSigmoid(output); for(int i=0;i<ArraySize(weights);i++){ weight_adjustments[i]+=error*previous_layer_nodes[i].output; } bias_adjustment+=error; }
با این واقعیت که ما اضافه می کنیم گیج نشوید، ما فقط در حال جمع آوری کل تنظیمی هستیم که قرار است در پایان دسته روی این وزن اعمال کنیم (و همچنین تعصب).
جادویی درسته؟ ما خطا را گرفتیم، آن را باز کردیم و اکنون می دانیم که وزن برای این اصلاح چقدر باید تغییر کند.
عالی است و حالا ببینید قسمت دیگر چقدر ساده است (انتشار برگشتی، یعنی پخش کردن خطا به عقب)
یک گره لایه قبلی چقدر برای خطای این لایه “مسئول” است؟
ساده است، مقدار وزن مسئول است، شما دقیقاً همین کار را انجام می دهید تا خطا را به گره های لایه قبلی برگردانید:
void back_propagation(bool propagate_error, snn_node &previous_layer_nodes[]){ error*=derivativeSigmoid(output); if(propagate_error){ for(int i=0;i<ArraySize(previous_layer_nodes);i++){ previous_layer_nodes[i].error+=weights[i]*error; } } for(int i=0;i<ArraySize(weights);i++){ weight_adjustments[i]+=error*previous_layer_nodes[i].output; } bias_adjustment+=error; }
این همان است , تمام ریاضیات و معادلات منجر به آن تابع کوچک بالا می شود .
عالی است، اکنون باید این تابع را از یک لایه نیز فراخوانی کنید، بنابراین بیایید آن را در آنجا نیز اضافه کنیم.
نگران کل ساختار گره نباشید، کد منبع کامل شامل در پایین این وبلاگ ضمیمه شده است.
بنابراین، تابع لایه پشت سرپا، چه چیزی را باید ارسال کنیم؟ این که آیا باید به لایه قبلی و لایه قبلی پس انتشار دهیم یا نه.
سپس در گره ها حلقه می زنیم و انتشار برگشتی را برای هر یک از آنها فراخوانی می کنیم:
این برای ساختار لایه است
void back_propagation(bool propagate_error, snn_layer &previous_layer){ for(int i=0;i<ArraySize(nodes);i++){ nodes[i].back_propagation(propagate_error,previous_layer.nodes); } }
عالی است، و اجازه دهید مشکل دیگری را که احتمالاً در حال حاضر درباره آن فکر می کنید، حذف کنیم.
چگونه خطای لایه خروجی را دریافت کنیم، آیا به یک تابع برای آن نیاز نداریم؟
بله، و این نیز به همین سادگی است:
ما یک تابع برای محاسبه خطا در گره های خروجی شبکه ایجاد می کنیم.
ما به آن یک نام متمایز می دهیم تا تصادفی آن را صدا نکنیم
و چه چیزی را در آنجا ارسال می کنیم؟ پاسخ های صحیح نمونه !
خودشه . و انتظار داریم چه چیزی به ما بازگردد؟ مقدار تابع ضرر
و اینجاست که همه درجههای درجه دوم و hellingers و itakura-saiko و کلمات buzz متقابل آنتروپی وارد میشوند.
این تابعی است که آنها را در آن قرار می دهید.
برای این مثال از ساده ترین تابع از دست دادن درجه دوم استفاده می کنیم.
این تابع در ساختار لایه نیز وجود دارد
double output_layer_calculate_loss(double &correct_outputs[]){ double loss=0.0; for(int i=0;i<ArraySize(correct_outputs);i++){ loss+=MathPow((nodes[i].output-correct_outputs[i]),2.0); } loss/=2.0; for(int i=0;i<ArraySize(nodes);i++){ nodes[i].error=nodes[i].output-correct_outputs[i]; } return(loss); }
عالی، حالا بیایید مکث کنیم و فکر کنیم.
ما 2 چیز را از دست دادهایم، 1 اینکه چگونه ساختار شبکه خطا را مدیریت میکند و پسپخش میکند، 2 چگونه شبکه یاد میگیرد.
زمان استراحت برای نوشیدن قهوه .

بیایید چند چیز بکشیم
شبکه نمونه ای را دریافت می کند که ما یک نتیجه مشخص برای آن داریم و “پارامترها/ویژگی ها/ورودی ها” این نمونه را به لایه ورودی فشار می دهیم.
شروع بهمنی از محاسبات:

شبکه با f پیشبینی پاسخ میدهد (که در زبان آکادمیک “بردار” است، در زبان ما آرایهای است که میتواند به هر طولی باشد.
سپس آرایه دیگری داریم که مقادیر صحیحی برای این نمونه است، بگذارید آن را C (بردار نتایج شناخته شده در زبان آنها) بنامیم.
و کاری که اکنون باید انجام دهیم این است که C را با f و :
- با استفاده از هر یک از معادلاتی که معلمان صورت ما را با آن پر کرده اند بدون اینکه توضیح دهند به کجا می روند، برای این نمونه چقدر شبکه اشتباه است. 🤣، jk)
- سپس اندازه گیری کنید که هر گره از خروجی ما چقدر اشتباه است
- سپس این خطاها را به لایه 1 برگردانید و تنظیمات وزن را برای شبکه ثبت کنید
بیایید به صورت حرفه ای این را ترسیم کنیم:

خوب، “خروجی” چیست؟ آخرین لایه شبکه است و آرایه f چیست؟ آرایه گره های آخرین لایه شبکه است.
بنابراین، به ساختار شبکه بازگردیم،
ما یک عدد صحیح samples_calculated اضافه می کنیم که تعداد نمونه هایی را که با چشم نارنجی درست در آنجا “دیده ایم” اضافه می کنیم، و یک مجموع_از دست دادن دوبرابر که میزان اشتباه این “مجموعه” را اندازه گیری می کند (کلمات کلیدی دیگری وجود دارد که از هیچ جا ظاهر شد، در هر چند زمان مناسب) در مجموع از معادلات جادویی هوشمندتر از آنچه ما مردم ارائه کرده ایم استفاده می کند.
اما صبر کنید، ما این معادلات را روی تابع محاسبه ضرر نوشتیم. آها پس در ساختار شبکه چه خواهیم کرد؟
ما نمونه های محاسبه شده را افزایش خواهیم داد و آخرین لایه ها را محاسبه تابع ضرر فراخوانی می کنیم. و همین است!
void calculate_loss(double &sample_correct_outputs[]){ samples_calculated++; total_loss+=layers[ArraySize(layers)-1].output_layer_calculate_loss(sample_correct_outputs); }
آسان درست است؟ اما یک دقیقه صبر کنید، چیز output_layer_blabla نیز خطای گره های لایه خروجی را برای ما آماده کرد، درست است؟
بله، این بدان معناست که اکنون میتوانیم انتشار مجدد را برای کل شبکه فراخوانی کنیم، اما برای راحتی کار، اجازه دهید تابع را از هم جدا کنیم.
void back_propagation(){ for(int i=ArraySize(layers)-1;i>=1;i--){ layers[i].back_propagation(((bool)(i>1)),layers[i-1]); } }
همین است، ما از آخرین لایه شروع می کنیم تا لایه 1، و به یاد می آوریم که اگر لایه 1 است یک “false” ارسال کنیم زیرا نمی توانیم خطا را به لایه 0 (که لایه ورودی است) منتشر کنیم.
جادو تقریباً تمام شده است. زمانی که شما ()back_propagation را در ساختار شبکه فراخوانی می کنید، شبکه شما آماده “یادگیری” است.
خب بیا انجام بدیمش
ببینید چقدر ساده است، وقتی آن را می بینید و آن را با شش تخته پر از معادلات در ویدیوی mit که برای اولین بار تماشا کرده اید مقایسه می کنید، گوش های خود را باور نخواهید کرد.
ما به ساختار گره برمی گردیم، خوب؟
بیایید فرض کنیم همه انتشارهای برگشتی کامل شده اند.
باید چکار کنیم؟
آرایه weight_adjustments (که اصلاحات را جمع آوری کرده است) را به آرایه وزن ها اضافه کنید. و این کار را برای تعصب نیز انجام دهید.
ما باید چه چیزی را ارسال کنیم؟ نرخ یادگیری
void adjust(double learning_rate){ for(int i=0;i<ArraySize(weights);i++){ weights[i]-=learning_rate*weight_adjustments[i]; } bias-=learning_rate*bias_adjustment; reset_weight_adjustments(); }
6 خط کد، و خط ششم را فراموش نمی کنیم که تنظیم مجدد را صدا کنیم، و تمام، این گره “یاد گرفت”.
لایه چطور؟
void adjust(double learning_rate){ for(int i=0;i<ArraySize(nodes);i++){ nodes[i].adjust(learning_rate); } }
همان چیزی است که ما نرخ یادگیری را ارسال می کنیم، به گره های خود می رود و فراخوانی تنظیم می شود.
در مورد کل شبکه چطور؟
void adjust(double learning_rate){ for(int i=1;i<ArraySize(layers);i++){ layers[i].adjust(learning_rate); } }
همان چیزی است، نرخ یادگیری در، همه لایه ها (به جز 0) را فراخوانی می کند و گره ها را تنظیم می کند
تمام است، شما اکنون یک کتابخانه شبکه عصبی ساده در حال کار دارید.
اما صبر کنید، بیایید چند دریبل دیگر انجام دهیم.
آیا شگفت انگیز نیست اگر شبکه سرعت یادگیری خود را با بهتر شدن و بهتر شدن کاهش دهد؟ آره
آیا میتوانیم ابزاری را در اختیار رمزگذار (شما) قرار دهیم تا آن را محاسبه کند؟
آره. ما می توانیم محاسبه ای از حداکثر تلفات احتمالی در هر نمونه و تلفات جاری در هر نمونه ارائه کنیم.
ما آنها را به ساختار شبکه متصل میکنیم:
double get_max_loss_per_sample(){ double max_loss_per_sample=((double)ArraySize(layers[ArraySize(layers)-1].nodes))/2.0; return(max_loss_per_sample); } double get_current_loss_per_sample(){ double current_loss_per_sample=total_loss/((double)samples_calculated); return(current_loss_per_sample); } void reset_loss(){ total_loss=0.0; samples_calculated=0; }
ما همچنین یک تابع بازنشانی از دست دادن را برای زمانی که یک دسته جدید را شروع می کنیم اضافه می کنیم. اما صبر کنید آن چیست، حداکثر تلفات گره های آخرین لایه تقسیم بر 2 است؟
بله برای تابع از دست دادن درجه دوم ما استفاده می کنیم.
بیایید سریع معادله را ببینیم، این ضرر در هر نمونه است:

این است که شما پیش بینی شبکه را در هر گره i می گیرید و پاسخ صحیح را برای آن گره کم می کنید، اختلاف را مربع می کنید و این را برای تمام گره های خروجی جمع می کنید، سپس بر 2 تقسیم می کنید.
اگر همه گره ها اشتباه باشند، بیشترین مقداری که این معادله می تواند به ازای هر گره بیرون بیاورد چیست؟ (و با در نظر گرفتن خروجی های تابع سیگموئید از 0.0 تا 1.0) , 1 , -1 مربع و 1 مربع برابر 1 . بنابراین مجموع گره های خروجی بر 2 , به این ترتیب به آنجا رسیدیم . اگر از توابع مختلف از دست دادن استفاده می کنید، باید آن را تغییر دهید.
جالب است، بیایید ببینیم چگونه با استفاده از این کتابخانه یک شبکه را برای مشکل xor تنظیم کنیم.
بیایید این را مستقر کنیم:
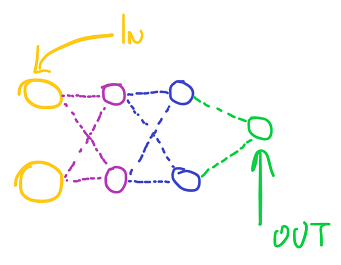
snn_net net; net.add_layer().setup(2); net.add_layer().setup(2,2); net.add_layer().setup(2,2); net.add_layer().setup(1,2);
آسان. و چگونه کار آموزشی را انجام دهیم؟
بیایید این کار را برای مشکل Xor انجام دهیم، به 2 ویژگی و 1 خروجی نیاز داریم
double features[],results[]; ArrayResize(features,2,0); ArrayResize(results,1,0); for(int i=0;i<1000;i++) { int r=MathRand(); if(r>16000){features[0]=1.0;}else{features[0]=0.0;} r=MathRand(); if(r>16000){features[1]=1.0;}else{features[1]=0.0;} if(features[0]!=features[1]){results[0]=1.0;}else{results[0]=0.0;} net.feed_forward(features); net.calculate_loss(results); net.back_propagation(); } net.adjust(0.1); net.reset_loss();
پس چیکار کردیم؟ ما روی یک دسته از 1000 نمونه با یک پاسخ شناخته شده آموزش دیدیم:
- اولین ویژگی 0 یا 1 را تصادفی می کنیم، سپس دومی را در آرایه ویژگی ها ذخیره می کنیم.
- سپس نتیجه صحیح را محاسبه کرده و در آرایه نتایج (که اندازه آن 1 است) قرار می دهیم.
- سپس با ریختن ویژگی های این نمونه، پیشخور شبکه را (در هر نمونه) فراخوانی می کنیم
- سپس محاسبه ضرر را فراخوانی می کنیم و آرایه نتایج صحیح را ارسال می کنیم (برای این نمونه، آرایه نتایج به اندازه گره های لایه آخر است)
- سپس برای 1000 نمونه تنظیمات را منتشر و جمع آوری می کنیم.
- با خروج از حلقه، تنظیمات جمع آوری شده را با نرخ یادگیری 0.1 انجام می دهیم
- و سپس ضرر را بازنشانی می کنیم (آمار تلفات کل و نمونه های محاسبه شده)
عالی است، و چگونه نرخ یادگیری را بر اساس ضرر تنظیم کنیم؟
double max_loss=net.get_max_loss_per_sample(); double cur_loss=net.get_current_loss_per_sample(); double a=(cur_loss/max_loss)*0.1; net.adjust(a); net.reset_loss();
ما حداکثر تلفات ممکن را در هر نمونه دریافت می کنیم و اتلاف فعلی در هر نمونه را دریافت می کنیم.
ما تلفات جاری را بر حداکثر تلفات تقسیم می کنیم، بنابراین اگر حداکثر تلفات ممکن را در هر نمونه داشته باشیم، 1 را برمی گرداند.
سپس نتیجه این تقسیم در نرخ یادگیری پایه ضرب می شود (در مثال ما 0.1)
و سپس تابع تنظیم را با آن مقدار فراخوانی می کنیم.
بنابراین اگر تلفات حداکثر به ازای هر نمونه 0.1 برگرداند، نرخ یادگیری 0.1 * 0.1 = > 0.01 را دریافت خواهیم کرد، با نزدیک شدن به راه حل، سرعت یادگیری شما با رسیدن به قلمرو جام مقدس کاهش می یابد. 😋
همین است، من کد منبع و نمونه یک شبکه xor را پیوست می کنم.


[ad_2]
لینک منبع : هوشمند نیوز
 آموزش مجازی مدیریت عالی حرفه ای کسب و کار Post DBA آموزش مجازی مدیریت عالی حرفه ای کسب و کار Post DBA+ مدرک معتبر قابل ترجمه رسمی با مهر دادگستری و وزارت امور خارجه |  آموزش مجازی مدیریت عالی و حرفه ای کسب و کار DBA آموزش مجازی مدیریت عالی و حرفه ای کسب و کار DBA+ مدرک معتبر قابل ترجمه رسمی با مهر دادگستری و وزارت امور خارجه |  آموزش مجازی مدیریت کسب و کار MBA آموزش مجازی مدیریت کسب و کار MBA+ مدرک معتبر قابل ترجمه رسمی با مهر دادگستری و وزارت امور خارجه |
 مدیریت حرفه ای کافی شاپ |  حقوقدان خبره |  سرآشپز حرفه ای |
 آموزش مجازی تعمیرات موبایل آموزش مجازی تعمیرات موبایل |  آموزش مجازی ICDL مهارت های رایانه کار درجه یک و دو |  آموزش مجازی کارشناس معاملات املاک_ مشاور املاک آموزش مجازی کارشناس معاملات املاک_ مشاور املاک |
- نظرات ارسال شده توسط شما، پس از تایید توسط مدیران سایت منتشر خواهد شد.
- نظراتی که حاوی تهمت یا افترا باشد منتشر نخواهد شد.
- نظراتی که به غیر از زبان فارسی یا غیر مرتبط با خبر باشد منتشر نخواهد شد.





ارسال نظر شما
مجموع نظرات : 0 در انتظار بررسی : 0 انتشار یافته : 0