
The simplest XOR gate neural network for mql5 🍺 part1 – Neural Networks – 3 April 2023
[ad_1] XOR Gate example neural network in mql5 , as simple as possible 🍺 I’ll assume you know what the XOR gate “problem” is . A quick refreshing pro schematic : The first 2 columns are the 2 inputs and the third column is the expected result from that operation . So 0v0=0 1v0=1 0v1=1

[ad_1]
XOR Gate example neural network in mql5 , as simple as possible 🍺
I’ll assume you know what the XOR gate “problem” is .
A quick refreshing pro schematic :
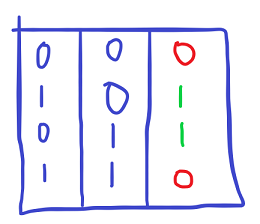
The first 2 columns are the 2 inputs and the third column is the expected result from that operation . So 0v0=0 1v0=1 0v1=1 1v1=0
It is a neat little task to let a nn have a go at and its simple enough to allow discovery of our errors , in code or in the interpretation of the maths.
This is how the resulting net will look like
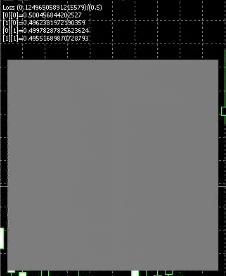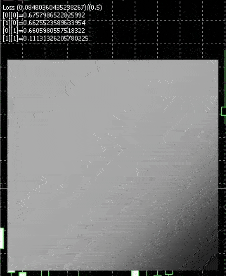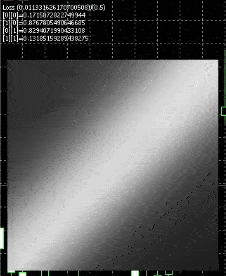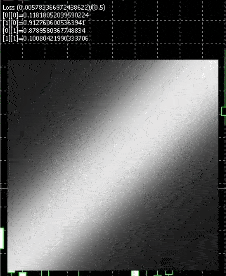
White represents nodes firing , we have a square display for testing , and , we feed in inputs 0 to 1 for both axis , so it fires when the x axis approaches 1 or the y axis approaches 1.
What we’ll do here , we will create 3 simple structures :
- A neural node
- A neural layer with nodes
- A neural net with layers with nodes
Sco
I recall some of the questions i had starting out so i’ll share the answers (that may not be 100%) here :
- “Do i need to divide the weight adjustments (to learn) by the number of batches?” – No
- “A node connects forward to multiple other nodes , do i need to average out the error it receives?” – No
- “Why is the loss function i’m using to backpropagate the error different than the loss function i’m using to calculate the cost or the how wrong the overall net is ?” – Its not different , the loss you send per node for back propagation is the derivative of the loss function you use to calculate the “cost”
- “Why do i send a -= in the weight adjustments and not a +=”? – it has to do with math and that the derivatives are the velocity of the current heading of the overall network or something , i was stuck on this simple thing for a long time but thankfully its just a sign switch . I don’t have a proper explanation for that.
- “Do i need to calculate the error from the loss function per output node separately ? “ – yes each node has its own error (which is the derivative of the loss function)
- “Do i back propagate with the old weights or the adjusted weights ?” – the old weights
To the task !
A.The nodes :
i won’t bore you with the why’s and theory , actually the web is full of that .What i recall from the days i started -trying- to learn that is : longing for a f********ng simple source code (on any language) that actually explained what was going on and not just reciting math or using a python library.
So :
what types of nodes are there ?
- An input node
- A node of a hidden or dense layer
To simplify
- A node that does not adjust its weights nor does it receive error (input)
- A node that adjusts its weights and receives error (from forward layers or the result we seek itself)
How will we deploy nodes here ?
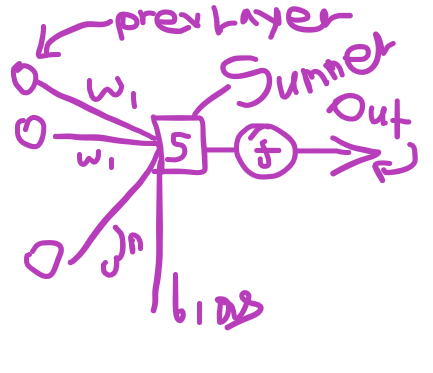
Consider the little ball with the f on it the node of which the class we’ll type out right now.
f is the activation function also which spits out an output (out)
Summer is the summation of all the weights multiplied by each node of the previous layer and of course the bias.
When you draw schematics for your net at first draw the summers too , it helps with derivatives .
The activation function we’ll use is , what else , the sigmoid .
So let’s blurt this function out :
double activationSigmoid(double x){ return(1/(1+MathExp(-1.0*x))); }
and of course the dreaded derivative :
double derivativeSigmoid(double activation_value){ return(activation_value*(1-activation_value)); }
Okay , ready ? class snn_node (simple neural net)
What is the first thing we need ? the weights
Well how many weights ? it depends on each previous layer , that means an array !
Also we’ll need a bias and some basic stuff
class snn_node{ public: double weights[]; double bias; snn_node(void){reset();} ~snn_node(void){reset();} void reset(){ ArrayFree(weights); bias=0.0; } };
Okay , but won’t we need a way to set this up ? yes !
What do we need to send to the setup function ? the number of nodes the previous layer has . Why ? because we will have one weight for each
node of the previous layer.
so our setup will look like this :
void setup(int nodes_of_previous_layer){ ArrayResize(weights,nodes_of_previous_layer,0); }
At this point you remembered that you need to randomize the weights at first . Well we can create a neat little function for that :
void init_weights(double min,double max){ double range=max-min; for(int i=0;i<ArraySize(weights);i++){ weights[i]=(((double)MathRand())/32767.0)*range+min; } bias=(((double)MathRand())/32767.0)*range+min; }
(we also initialize the bias)
So what happened here ?
- We receive a minimum and maximum value that the random weights must have
- we then calculate the range of the weights by subtracting the minimum from the maximum (ex min=-1 max=1 range=2)
- we then cycle in the # of weights -how do we know the # of weights? the function will be in the node class- we ask mql5 for a random number from 0 to 32767
- we turn it to a double type
- we divide it by the max range of the random function (32767.0) this way we get a value from 0 to 1
- then we multiply that 0 to 1 value with the range we want our weights to have
- and finally we add the minimum
- Quick example (0.5)*range+min=(0.5)*2-1.0=0.0 , 0.5 that was in the middle of 0 to 1.0 is in the middle of -1.0 to 1.0 , perfection.
Wait , can we include this function in the class and also have it linked to the setup function ? yes
void setup(int nodes_of_previous_layer, bool randomize_weights=true, double weights_min=-1.0, double weights_max=1.0){ ArrayResize(weights,nodes_of_previous_layer,0); if(randomize_weights){ init_weights(weights_min,weights_max); }else{ ArrayFill(weights,0,nodes_of_previous_layer,1.0); bias=1.0; } }
So now the node setup has the initial randomizer on by default with default weights range -1.0 to 1.0 , if the user (coder) wants to change it they will type it in.
Now let’s think , we have the node and the weights to the previous layer , what else do we need ?
That’s right what do we do when we receive an error , and where will we store it and what will we process first ?
well , let’s relax

nice , here is the order :
We will be calculating the error at the output (rightmost end) , then per layer we will send the error back to each node of the previous layer , in sequence , in order . So our little node will need to store the error it receives somewhere , why ? because until the layer that is currently backpropagating finishes we need to keep summing up the error that the node is responsible for .
Confusing ? okay , again , you are selling an algorithm , you send your offer to 3 buyers . When the first buyer answers you wont immediately accept or decline , you’ll wait for the other 2 and then its your turn.
Similarly but not at all a node is responsible for the nodes of the next layer it links out to .
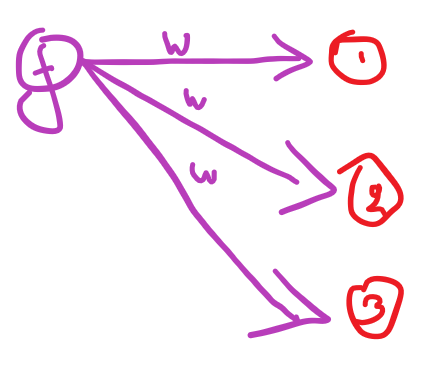
The node f is responsible for errors on the next layer’s node 1 node 2 and node 3 so when they backpropagate (when they point the finger at node f saying its it’s fault) node f needs to know how much of a “bad boy” it is . What does that depend on ? the weights 🙂 Node f has a partial responsibility for the mistakes each of the nodes of the next layer do , and the network’s mistakes as a whole too.
Got it ? great , all that just to add a variable to the class 😂
And we’ll also add an output variable because the following layers will need to read from this node too.
double error; double output;
And right about here we arrive at exciting moment numero uno . The calculation of the node or the “feed forward” .
What do we do on the feed forward , come on you know , that’s the easy sh*t .
We take the node outputs of the previous layer multiplying each one by the weight , at the end of that sum we slap on the bias and then we pass that through the activation function , and we have the output of the node .
We also reset the error (=0.0) , why ? because this variable will hold and transfer , or rather , infect the nodes with the error value for one sample only .(for each sample)
and here’s how it looks :
void feed_forward(snn_node &previous_layer_nodes[]){ output=0.0; error=0.0; for(int i=0;i<ArraySize(previous_layer_nodes);i++){ output+=previous_layer_nodes[i].output*weights[i]; } output+=bias; output=activationSigmoid(output); }
Self explanatory right ?
to calculate this node :
- we call the feed_forward
- we send in an array with the nodes of the previous layer
- we set the output and the error to 0.0
- we loop in the total nodes of the previous layer – which is the same amount as the weights of this node
- we add the previous node’s output value x the weight , they have the same [i] index , duh
- out of the loop we add the bias value
- then we pass it through the activation function we built earlier
and that node is baked ready to be used by the next layer
Awesome

Onwards
Now , time to face the hard stuff . At some point we know we’ll need to tackle the dreaded backpropagation .
What does that mean ? let’s think .
The backpropagation will calculate something right ? and that something will be used to adjust the weights of the nodes .
But we cannot adjust the weights immediately so we need a …. yes another array for the weight adjustments .
We will dump all the changes the weights need to undergo in that array (so same size as the weights) , and
then when we want to make the network “learn” we’ll use that collection of adjustments .
Is this the only way ? no , but , it helps keep things simple and more understandable at first .
So , let’s add the weight adjustments array , we’ll call it weight adjustments 😛
Don’t forget , we must size it on setup of the node along with the weights and initialize it to 0.0 !
We will also need to adjust the bias , so , we also add a bias adjustment value
double weight_adjustments[]; double bias_adjustment; void reset_weight_adjustments(){ for(int i=0;i<ArraySize(weight_adjustments);i++){ weight_adjustments[i]=0.0; } bias_adjustment=0.0; }
and because we are smart we added a reset adjustments function for convenience.
Cool now its time to deploy the layers first and then we will come back for the backprop.
Let’s take a break , and look at the things we have so far …

amazing right ? you are one backprop function ,one layer structure and one network structure away from your neural net library !
so …
B.The Layers
For the layers we need to keep in mind that there will be 2 kinds . The input layer and the hidden layers (and output layer) , the non input layers in other words , or the layers that learn and one layer that does not learn . So :
what does a layer have ? nodes
class snn_layer{ public: snn_node nodes[]; };
pfft , easy sh*t…
What else do we need ? to setup the layer , and , the basic stuff , reset , constructor destructor etc.
And for the setup we will have two versions . One with just the number of nodes for the layer , for input layers and one with the number of nodes , the number of nodes of the previous layer and some other options . We will essentially be able to setup the layer and its nodes instantly .
That’s what we want , and here is how it turns out :
class snn_layer{ public: snn_node nodes[]; snn_layer(void){reset();} ~snn_layer(void){reset();} void reset(){ ArrayFree(nodes); } void setup(int nodes_total){ ArrayResize(nodes,nodes_total,0); } void setup(int nodes_total, int previous_layer_nodes_total, bool randomize_weights=true, double weights_min=-1.0, double weights_max=1.0){ ArrayResize(nodes,nodes_total,0); for(int i=0;i<ArraySize(nodes);i++){ nodes[i].setup(previous_layer_nodes_total,randomize_weights,weights_min,weights_max); } } };
The first setup just resizes the nodes array , so the layer has nodes , and its probably an input layer.
the second setup receives the number of nodes to deploy , and also sets up the nodes based on the nodes # of the previous layer (for the weights of each node) and , some optional weight initialization options . The second setup essentially prepares the layer fully for operation .
Excellent , what else ? how will we be calling the calculation (the feed forward) of each node ?
We will have a function on the layer too which in turn will call all its nodes to be calculated . neat
What will that function need to receive though ? hmm , what do the nodes of this layer depend on for their calculation ?
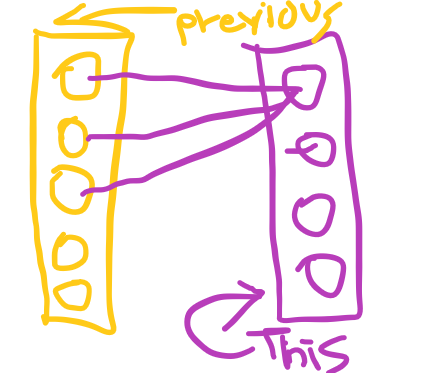
the weights and the previous layer , aha! so the “feed forward” call of this layer should receive the previous layer :
void feed_forward(snn_layer &previous_layer){ for(int i=0;i<ArraySize(nodes);i++){ nodes[i].feed_forward(previous_layer.nodes); } }
that’s it , that’s the function :
- we send the previous layer in
- we loop to the nodes of this layer
- for each node we call it’s feed forward and we send the what ? the array of nodes of the previous layer
- handy
But wait … what about the input layer ? Ah , the input layer has no calculation but we just need to send in the values right ?
Let’s create a function for that too :
void fill_as_input_layer(double &inputs[]){ for(int i=0;i<ArraySize(nodes);i++){ nodes[i].output=inputs[i]; } }
?…what? that’s it ? yep . You send the inputs array of a sample and it fills the input layer output values , of each node . We give it a distinct name so that we do not call the wrong function by accident , but more or less that’s it with the feed forward.
Let’s go for the net structure and then do the hard stuff .
C.The Network
what does the networ… layers
class snn_net{ public: snn_layer layers[]; snn_net(void){reset();} ~snn_net(void){reset();} void reset(){ ArrayFree(layers); } };
so , an array of layers , and the basic stuff , awesome . Will we need a setup function ? mmmmm nope , we can add a layer addition function
that returns a pointer to the new layer and we can directly play with the returned pointer .(i.e. set the new layer up right then and there using the layer functions) :
snn_layer* add_layer(){
int ns=ArraySize(layers)+1;
ArrayResize(layers,ns,0);
return(GetPointer(layers[ns-1]));
}
Now when we call : net.add_layer() we’ll be able to keep typing and call the setup function directly for that layer.
Great , and of course , the feed forward function , right ? what will that need ?
Wrong , it needs the array of inputs for the sample it will calculate , and here’s how it looks :
void feed_forward(double &inputs[]){ layers[0].fill_as_input_layer(inputs); for(int i=1;i<ArraySize(layers);i++){ layers[i].feed_forward(layers[i-1]); } }
So what does it do ? :
- receive a list of input values
- then these go in the first layer (fill as input layer)
- then we loop from layer 1 to the last layer
- and we call the feed forward for each layer
- and we send the layer i-1 to the feed forward function (each previous layer)
And that is it , the feed forward part is complete .
How about we also give it a function that returns the result of a specific output node ?
yes . What is an output node ? a node on the last layer !
so the function will look like this :
double get_output(int ix){ return(layers[ArraySize(layers)-1].nodes[ix].output); }
go to the last layer , and return the output value of that node , simple right ?
Ok ,now , take a big break because we’ll dive to
the hardest part of it all …
Ready ? excellent
Continue to part2


[ad_2]
لینک منبع : هوشمند نیوز
 آموزش مجازی مدیریت عالی حرفه ای کسب و کار Post DBA آموزش مجازی مدیریت عالی حرفه ای کسب و کار Post DBA+ مدرک معتبر قابل ترجمه رسمی با مهر دادگستری و وزارت امور خارجه |  آموزش مجازی مدیریت عالی و حرفه ای کسب و کار DBA آموزش مجازی مدیریت عالی و حرفه ای کسب و کار DBA+ مدرک معتبر قابل ترجمه رسمی با مهر دادگستری و وزارت امور خارجه |  آموزش مجازی مدیریت کسب و کار MBA آموزش مجازی مدیریت کسب و کار MBA+ مدرک معتبر قابل ترجمه رسمی با مهر دادگستری و وزارت امور خارجه |
 مدیریت حرفه ای کافی شاپ |  حقوقدان خبره |  سرآشپز حرفه ای |
 آموزش مجازی تعمیرات موبایل آموزش مجازی تعمیرات موبایل |  آموزش مجازی ICDL مهارت های رایانه کار درجه یک و دو |  آموزش مجازی کارشناس معاملات املاک_ مشاور املاک آموزش مجازی کارشناس معاملات املاک_ مشاور املاک |
- نظرات ارسال شده توسط شما، پس از تایید توسط مدیران سایت منتشر خواهد شد.
- نظراتی که حاوی تهمت یا افترا باشد منتشر نخواهد شد.
- نظراتی که به غیر از زبان فارسی یا غیر مرتبط با خبر باشد منتشر نخواهد شد.





ارسال نظر شما
مجموع نظرات : 0 در انتظار بررسی : 0 انتشار یافته : 0